

Explore the World of Vector Databases for Machine Learning: An In-Depth Guide


Table of contents
- What are Vector Databases?
- Key Features of Vector Databases
- Use Cases for Vector Databases
- Examples of Vector Databases
- Challenges of Traditional Databases in Handling High-Dimensional Data
- Real-World Examples of Organizations Using Vector Databases
- Potential Limitations of Vector Databases
- Comparison with Alternative Methods for Handling High-Dimensional Data
- Technical Aspects of How Vector Databases Work
- Python Code Snippet using Milvus
With the emergence of AI and ML, businesses across various industries are striving to transform their operations through data-driven insights. Vector databases, a relatively new type of database adept at handling high-dimensional vector data, play a crucial role in powering these AI and ML systems.
What are Vector Databases?
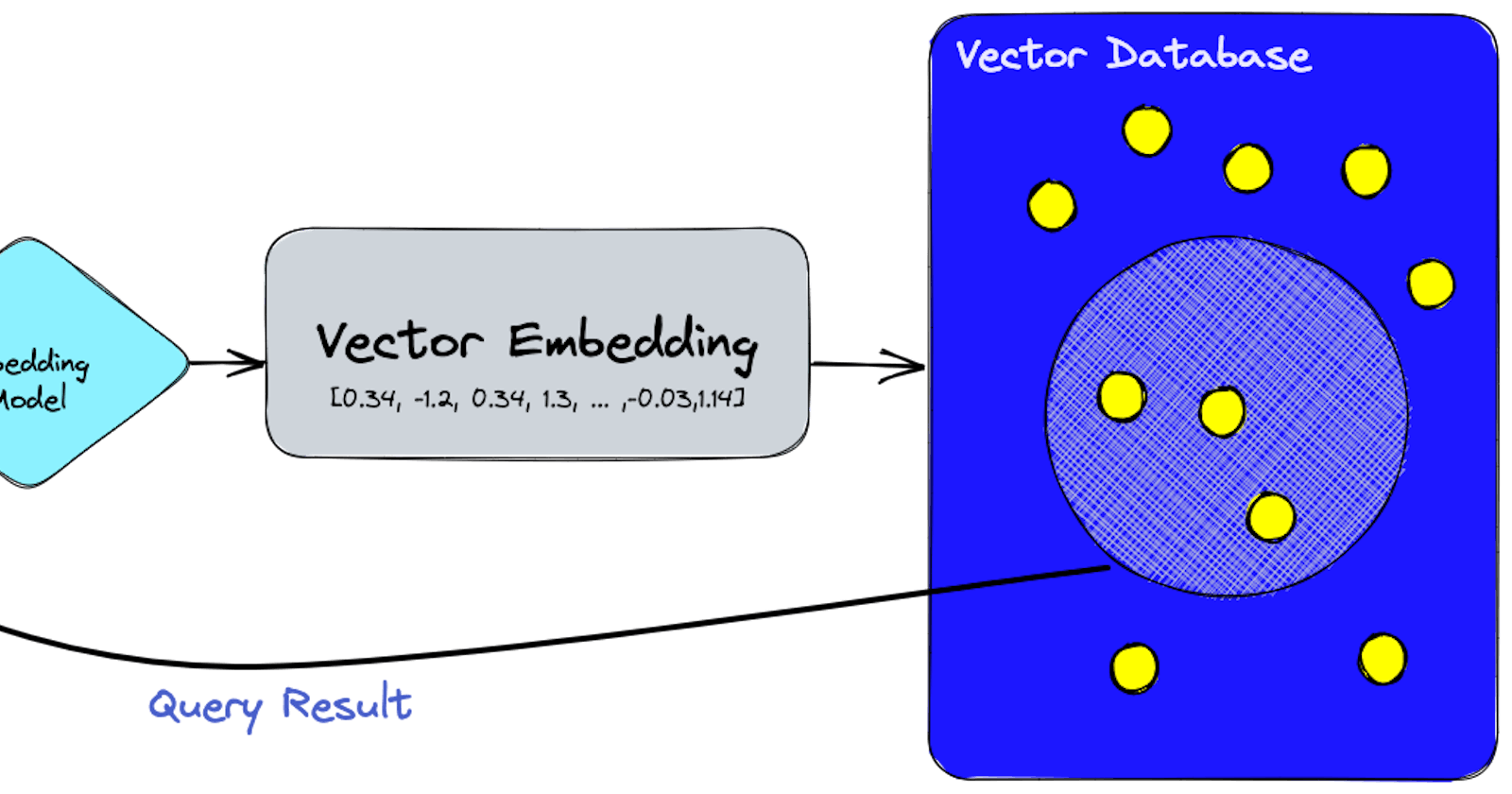
Vector databases, also known as vector search engines, are designed to store, manage, and query high-dimensional vectors effectively. They typically operate within the realm of machine learning, where objects (such as images, text, and so on) are represented as high-dimensional vectors. These vectors, generated from models like deep neural networks, capture the 'essence' or 'features' of the objects.
The power of a vector database lies in its ability to perform similarity searches among vectors. Given a query vector, the database efficiently finds the most similar vectors stored within it. This operation, often referred to as nearest neighbor search, is crucial for various AI tasks such as image recognition, recommendation systems, semantic search, and more.
There are a few different types of vector databases, generally categorized based on their architecture and implementation:
Open-source vector databases: These are freely available vector databases that allow for easy integration into applications. Examples include Milvus, FAISS (Facebook AI Similarity Search), and Annoy (Approximate Nearest Neighbors Oh Yeah) developed by Spotify.
Commercial vector databases: These are typically offered as part of a larger platform, with enhanced features and support options. Examples include Pinecone and Weaviate.
Cloud-based vector databases: These are offered as services by cloud providers and are fully managed, meaning that the cloud provider takes care of setup, management, and scaling. Examples include Amazon's Elasticsearch Service with its KNN (k-nearest neighbors) feature.
Database extensions: These are extensions or features added to an existing database to support vector operations. For example, PostgreSQL has the PGroonga extension that adds full-text search and vector support.
Hybrid databases: These databases combine the characteristics of traditional relational databases and vector databases, enabling efficient handling of structured and vector data in a single system. Examples include Vector.ai and Vespa.ai.
Each type of vector database has its own unique set of features, capabilities, and use cases, and the choice depends on the specific requirements of your application or project.
Key Features of Vector Databases
High-dimensional Vector Support: Vector databases are designed to handle high-dimensional data (data with hundreds or thousands of dimensions). They efficiently store and index these vectors for quick retrieval.
Similarity Search: The ability to perform nearest neighbor search is at the core of vector databases. This feature allows them to find vectors most similar to a given query vector, thereby enabling tasks like similarity search and recommendation systems.
Distributed Search: Many vector databases support distributed search across multiple nodes, allowing them to handle massive amounts of data and providing high availability.
Integration with Machine Learning: Vector databases are commonly used in conjunction with machine learning models and can be seamlessly integrated into an ML pipeline.
Use Cases for Vector Databases
Image and Video Recognition: By representing images or video frames as vectors, a vector database can quickly find similar images or videos based on visual content.
Recommendation Systems: Recommendation engines can utilize vector databases to efficiently find items similar to a given item or user profile, thereby providing personalized recommendations.
Semantic Search: By transforming text into high-dimensional vectors (using techniques like Word2Vec or BERT), vector databases can support semantic search, where documents are retrieved based on the meaning of the query rather than keyword matching.
Examples of Vector Databases
Milvus: An open-source vector database designed for AI and ML. It supports a variety of distance metrics and index types.
FAISS (Facebook AI Similarity Search): Developed by Facebook, FAISS is a library that provides efficient similarity search and clustering of dense vectors. It can be used to build vector databases.
Pinecone: A fully-managed vector database service designed for machine learning applications.
Challenges of Traditional Databases in Handling High-Dimensional Data
Dimensionality: The inherent complexity of high-dimensional data makes it difficult for traditional databases to manage. This problem is often referred to as the "curse of dimensionality". As the number of dimensions increases, the volume of the space increases so fast that the available data becomes sparse, making it challenging to perform effective data analysis.
Efficiency: Traditional databases are not equipped to handle the complexity of high-dimensional data and its operations. One of the most critical operations in machine learning and AI, the nearest neighbor search, is particularly inefficient when performed with traditional databases.
Indexing: Indexing is a powerful technique for optimizing data retrieval in traditional databases. However, it becomes less effective when dealing with high-dimensional data due to the increased sparsity of the data points.
Real-World Examples of Organizations Using Vector Databases
JD.com: China's largest online retailer, JD.com, uses Milvus, an open-source vector database, to power its product recommendation and similarity search systems. With the help of Milvus, JD.com can efficiently handle high-dimensional data derived from millions of products and deliver highly personalized product recommendations to its customers.
Tencent: Tencent uses vector databases for various applications, including image recognition, video analysis, and personalized recommendations. With a vector database, they can quickly retrieve similar images or videos based on visual content, improving the user experience across their services.
Potential Limitations of Vector Databases
While vector databases offer unique advantages in managing and querying high-dimensional data, they come with their own set of challenges:
Resource Intensive: As previously mentioned, vector databases can require substantial computational power and memory for indexing and querying high-dimensional vectors. This can result in a high cost of ownership for large-scale applications. To alleviate this, efficient hardware utilization and scaling strategies can be implemented. For instance, vector databases often support distributed systems, allowing you to spread the load over multiple machines, effectively handling more data and queries.
Complexity: Vector databases employ complex mathematical operations and algorithms to manage high-dimensional data efficiently. This complexity may pose a steep learning curve, especially for developers and data scientists unfamiliar with these techniques. To overcome this, extensive documentation, user-friendly APIs, and community support can be of significant help. Training programs and tutorials can also be useful in enhancing the understanding and usability of these databases.
Maturity: Given that vector databases are relatively new, they might not offer all the features available in more mature traditional databases. For example, transactional support or SQL-like query languages may not be fully developed. In the interim, hybrid solutions can be used, where traditional databases are used in parallel with vector databases, each handling the tasks they are best suited for. Over time, as the technology matures, more features are likely to be added to vector databases.
Data Security and Privacy: With the rise in data breaches and increasing focus on data privacy laws, security is a significant concern for databases. Given the novelty of vector databases, their security measures may not be as robust or well-tested as those in more established traditional databases. It is essential for organizations to conduct thorough security assessments and implement necessary security protocols and access controls to ensure data protection. Encryption of data at rest and in transit should also be a standard feature to prevent unauthorized access.
Integration with Existing Systems: Integrating a vector database into an existing tech stack can be a challenge, especially if the current systems are primarily built around traditional databases. Careful planning and design of the system architecture are necessary to ensure seamless integration. Moreover, the choice of a vector database should consider the support for various data formats, interfaces, and compatibility with existing tools and infrastructure.
Each of these potential limitations presents challenges that need to be addressed when implementing a vector database. However, with thoughtful design, appropriate use cases, and constant advancement in technology, these obstacles can be managed effectively. As the field continues to evolve, the advantages of vector databases for handling high-dimensional data in AI and ML applications will undoubtedly become more pronounced.
Comparison with Alternative Methods for Handling High-Dimensional Data
Traditionally, techniques like dimensionality reduction (PCA, t-SNE), space-filling curves, and bitmap indexes have been used to manage high-dimensional data. However, these methods have their limitations. For instance, dimensionality reduction techniques can result in loss of information, while bitmap indexes can become inefficient as the number of dimensions increases.
In contrast, vector databases are designed from the ground up to efficiently store, manage, and query high-dimensional data. They utilize specialized indexing techniques (like KD trees, ball trees, or HNSW) to accelerate the nearest neighbor search, making them a more suitable choice for applications requiring efficient similarity search.
Technical Aspects of How Vector Databases Work
Vector databases employ several techniques to effectively handle high-dimensional data:
Vector Representation: Objects (like images, text, etc.) are transformed into high-dimensional vectors using machine learning models. These vectors capture the 'essence' or 'features' of the objects and can be efficiently stored and managed in a vector database.
Indexing: Vector databases use specialized indexing structures (like KD-trees, ball trees, and HNSW) to organize the high-dimensional vectors. These indexes help in accelerating the nearest neighbor search by pruning the search space.
Querying: Given a query vector, the database searches for the most similar vectors in its storage. This operation is performed efficiently using indexes and similarity measures (like cosine similarity or Euclidean distance).
Distributed Search: To handle large-scale data and provide high availability, many vector databases support distributed search across multiple nodes. This feature allows them to scale horizontally by adding more nodes to the system.
Python Code Snippet using Milvus
Here's a simple example using the pymilvus Python SDK to interact with a Milvus vector database:
from pymilvus import Milvus, DataType
# Connect to Milvus server
client = Milvus(host='localhost', port='19530')
# Create a collection
collection_name = 'example_collection'
collection_param = {
"fields": [
{"name": "vector", "type": DataType.FLOAT_VECTOR, "params": {"dim": 128}},
],
"segment_row_limit": 4096,
"auto_id": True
}
client.create_collection(collection_name, collection_param)
# Insert vectors into the collection
vectors = [[0.1]*128, [0.2]*128, [0.3]*128, [0.4]*128] # 4 vectors with 128 dimensions
insert_param = {
"fields": [
{"name": "vector", "type": DataType.FLOAT_VECTOR, "values": vectors}
]
}
client.insert(collection_name, insert_param)
# Query the nearest neighbor
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
query_vector = [[0.15]*128] # Query vector
top_k = 1 # Number of nearest neighbors to return
results = client.search(collection_name, {"vector": {"topk": top_k, "query": query_vector, "params": search_params}})
for result in results:
print(f"ID: {result.id}, Distance: {result.distance}")
# Drop the collection
client.drop_collection(collection_name)
Some examples of interacting with different types of vector databases using Python.
Milvus: Open-source vector database.
from pymilvus import connections, DataType, FieldSchema, CollectionSchema, Collection
# create connection
connections.connect(alias='default')
# define fields
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
# create collection schema
schema = CollectionSchema(fields, description="test collection")
# create collection
collection = Collection(name="test01", schema=schema)
# insert some data
data = [
# IDs
[i for i in range(10)],
# 10 random 128-dimensional vectors
[[random.random() for _ in range(128)] for _ in range(10)]
]
mr = collection.insert(data)
# load data into memory
collection.load()
# search
results = collection.search(data[1], "embedding", param={"nprobe": 10}, limit=3)
# close connection
connections.remove_connection('default')
- FAISS (Facebook AI Similarity Search): Not exactly a database, but a library for efficient similarity search of dense vectors.
import numpy as np
import faiss
# dimension of vectors
d = 64
# create a random matrix (this will be our database)
db_vectors = np.random.random((10000, d)).astype('float32')
# create a random vector (this will be our query)
query_vector = np.random.random((1, d)).astype('float32')
# build the index
index = faiss.IndexFlatL2(d)
index.add(db_vectors)
# perform a search
D, I = index.search(query_vector, k=5)
# D contains the distances to the nearest neighbors
# I contains the indices of the nearest neighbors
print(I)
print(D)
Elasticsearch with KNN: Elasticsearch is a search engine based on the Lucene library. It supports vector data and KNN search through its KNN plugin.
from elasticsearch import Elasticsearch
es = Elasticsearch()
# create an index
es.indices.create(
index="my_vector_index",
body={
"mappings": {
"properties": {
"my_vector_field": {
"type": "knn_vector",
"dimension": 128
}
}
}
}
)
# add a document to the index
es.index(
index="my_vector_index",
id=1,
body={
"my_vector_field": [0.5, 0.5, 0.5, ...] # this should be a 128-dimensional vector
}
)
# search for the nearest neighbors
res = es.search(
index="my_vector_index",
body={
"size": 5,
"query": {
"knn": {
"my_vector_field": {
"vector": [0.5, 0.5, 0.5, ...], # this should be a 128-dimensional vector
"k": 5
}
}
}
}
)
print(res)
Note: For all examples, make sure you have the necessary libraries installed and the corresponding vector database running. Replace dummy data with actual data for practical use.