

Understanding Graph Databases: Structure, Advantages, and Use Cases
Graph Databases


Graph databases have garnered a lot of attention in the world of big data due to their ability to represent complex relationships in a natural, more human-readable way. But what exactly are graph databases, what features do they provide, and when should they be used?
What are Graph Databases?
Graph databases are a type of NoSQL database, created to address the limitations of relational databases. While relational databases can efficiently handle simple relationships between data points, they are not designed to handle complex, many-to-many relationships.
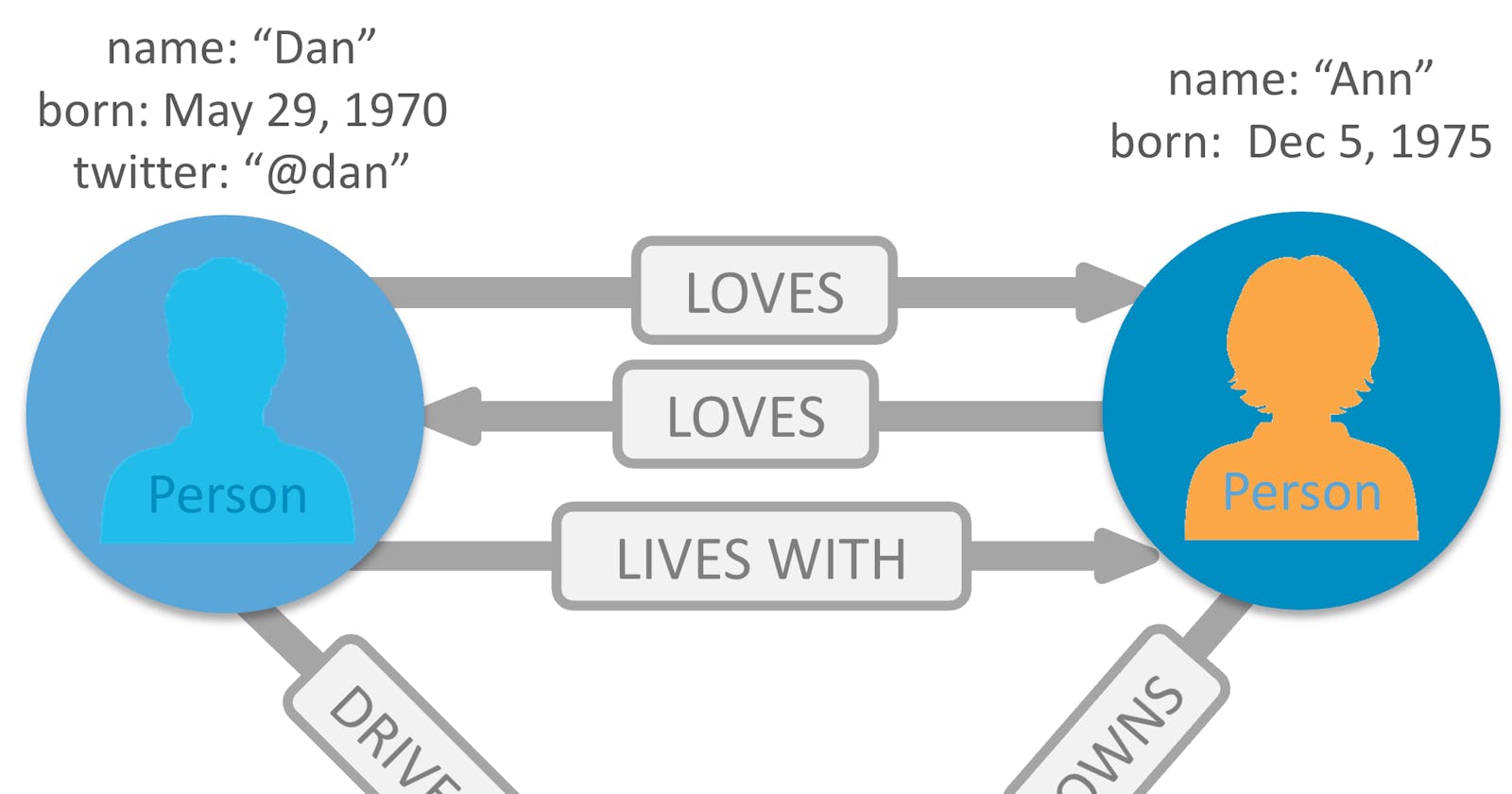
In a graph database, data is stored in nodes, which are like the records in a relational database. The relationships between nodes are stored in edges. Both nodes and edges can have properties, which are key-value pairs.
Key Features of Graph Databases
Relationship Handling: The primary purpose of graph databases is to handle complex relationships between data points. Relationships are not calculated at query time but are actually a part of the data, making querying relationships fast and efficient.
Schema-Free: Graph databases are generally schema-free, allowing you to add new kinds of relationships, nodes, and properties to your database on the fly.
Performance: Since relationships are integrated into the data, querying is extremely fast, even for complex join operations.
Advanced Analytics: Graph databases are used for sophisticated analytics and algorithms like shortest path, PageRank, and others. These operations are crucial in the fields of machine learning and artificial intelligence.
Use Cases for Graph Databases
Social Networks: Graph databases are ideal for modelling social networks. They can efficiently handle relationships between users, groups, events, and other data points.
Recommendation Engines: Based on user behavior, relationships between different data points can be established and used to recommend related items.
Fraud Detection: By finding unusual patterns and relationships, graph databases can be used to detect fraudulent activities.
Network and IT Operations: Graph databases can be used to model the relationships between different components in a network.
Examples of Graph Databases
Neo4j: The most popular graph database, known for its robustness, flexibility, speed, and ease of use.
Amazon Neptune: A fully-managed graph database service from Amazon Web Services.
Microsoft Azure Cosmos DB: A globally distributed, multi-model database service from Microsoft.
ArangoDB: An open-source, multi-model NoSQL database with a strong emphasis on graph processing.
Python Code Snippet using Neo4j
Here's a simple example of using the neo4j Python driver to interact with a Neo4j database:
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "password"))
def create_friendship(tx, name1, name2):
tx.run("MERGE (a:Person {name: $name1}) "
"MERGE (b:Person {name: $name2}) "
"MERGE (a)-[:FRIEND]->(b)",
name1=name1, name2=name2)
def print_friends(tx, name):
for record in tx.run("MATCH (a:Person)-[:FRIEND]->(friend) WHERE a.name = $name "
"RETURN friend.name ORDER BY friend.name", name=name):
print(record["friend.name"])
with driver.session() as session:
session.write_transaction(create_friendship, "Alice", "Bob")
session.read_transaction(print_friends, "Alice")
In this script, we first establish a connection to the Neo4j database, then define two functions for creating a friendship relationship and printing a person's friends. Finally, within a session, we create a friendship between Alice and Bob and print Alice's friends.
Let's explore another Python snippet using Neo4j where we create nodes and relationships, perform a complex query, and then delete a node:
from neo4j import GraphDatabase
uri = "bolt://localhost:7687"
driver = GraphDatabase.driver(uri, auth=("neo4j", "password"))
def create_company(tx, company_name):
tx.run("CREATE (c:Company {name: $company_name})",
company_name=company_name)
def hire_employee(tx, company_name, employee_name):
tx.run("MATCH (c:Company {name: $company_name}) "
"MERGE (e:Employee {name: $employee_name}) "
"MERGE (e)-[:WORKS_FOR]->(c)",
company_name=company_name, employee_name=employee_name)
def find_employees(tx, company_name):
result = tx.run("MATCH (e:Employee)-[:WORKS_FOR]->(c:Company {name: $company_name}) "
"RETURN e.name",
company_name=company_name)
return [record["e.name"] for record in result]
def delete_employee(tx, employee_name):
tx.run("MATCH (e:Employee {name: $employee_name}) "
"DETACH DELETE e",
employee_name=employee_name)
with driver.session() as session:
# Create a company node
session.write_transaction(create_company, "Tech Corp")
# Create employee nodes and establish relationships
session.write_transaction(hire_employee, "Tech Corp", "Alice")
session.write_transaction(hire_employee, "Tech Corp", "Bob")
# Print employees of Tech Corp
employees = session.read_transaction(find_employees, "Tech Corp")
print(employees)
# Delete an employee
session.write_transaction(delete_employee, "Alice")
# Print remaining employees of Tech Corp
employees = session.read_transaction(find_employees, "Tech Corp")
print(employees)
In this example, we're simulating a company-employee relationship. We create a company named "Tech Corp" and hire two employees, "Alice" and "Bob". We then find all employees working for "Tech Corp", delete "Alice", and find the remaining employees again.
The power of graph databases comes from the ability to directly express relationships and efficiently query them. This small example just scratches the surface of what is possible with graph databases like Neo4j.
As datasets grow and become more interconnected, the use of graph databases is likely to continue increasing. By representing data in a more natural form, graph databases allow for insightful and complex analysis that would be difficult to achieve with other database models.